平均値と標準偏差
統計の処理をする場合には、平均値や標準偏差のを求める時が多々あると思います。
そこで、データの平均値と標準偏差やデータのソート、正規分布、最小二乗法による直線近似を行うことにします。
1。 平均値と標準偏差
個のデータ があったとする。この平均値 、標準偏差 、分散 は
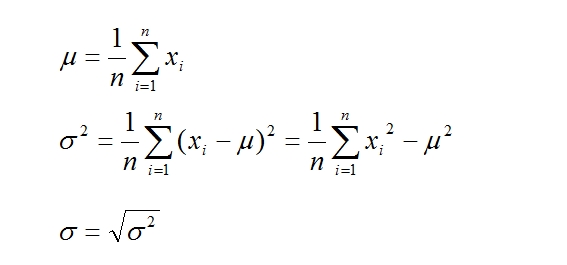 。
。
のように表される。ただし、データの個数が少ない場合には
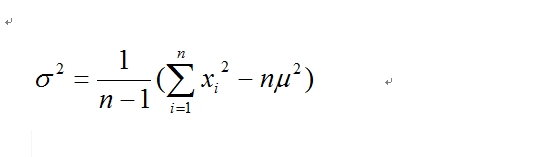
として計算をすします。データの個数が20個とかの場合に使用します。
計算例
例として、データ68, 72, 74, 61, 50, 80, 40, 70, 65, 81.の平均値 、標準偏差 、分散 を求めるプログラムを作成することにします。ここでは、次のようなプログラムを実行することにします。
1. x=[68 72 74 61 50 80 40 70 65 81] ;//データ
2. n=10; //データの個数
3. s=sum(x)
4. m=mean(x)
5. v2=(sum(x.^2)-n*m^2 )/(n-1)
6. v=sqrt(v2) //計算標準偏差
7. stdev(x) //組み込み標準偏差
–>s=sum(x)
s =
661.
–>m=mean(x)
m =
66.1
–>v2=(sum(x.^2)-n*m^2 )/(n-1)
v2 =
166.54444
–>v=sqrt(v2) //計算標準偏差
v =
12.90521
–>stdev(x) //組み込み標準偏差
ans =
12.90521
データの合計が661、平均66.1、 分散は 166.54444 、標準偏差は12.0952 のようになります。
mean:平均値の計算
stdev:組み込み標準偏差
2. データのソート:gsort
データソートには降順、昇順、配列のソート等があります。
[b,k]=gsort(a,option,direction)
のようにして使用します。ここで、aは実数か整数または文字列のベクトル行列です。
Optionで’r’を指定するとa の各列のソート、’g’:を指定すると行列の全要素のソート、’c’を指定するとの各行のソート、’lr’を指定すると列の辞書式ソート、’lc’を指定すると行の辞書式ソートをします。
directionで文字列の ソートの方向を指定します。 ‘i’ は昇順, ‘d’ は降順 (デフォルト)を意味します。また、bはaと同じ型と次元の配列で、kは整数値を有し行れるaと同じ次元の実数配列で元の添え字を有します。
// 各列のソート, ‘i’ は昇順,
1. a=[ 2 3 4 6 1 5]
2. [ a1,k]=gsort(a,’r’,’i’)
–>a=[ 2 3 4 6 1 5]
a =
2. 3. 4. 6. 1. 5.
–>[ a1,k]=gsort(a,’r’,’i’)
k =
1. 1. 1. 1. 1. 1.
a1 =
2. 3. 4. 6. 1. 5.
この行列は1行6列の行列なので、1列目には2だけです、同様に2列目は3、3列目は4,4列目は6,5列目は1,6列目は5です。
行列がそのまま、表示されることになります。
ご訪問ありがとうございます。
またお越し下さい。
関連記事
-
-
正規分布と相関係数
正規分布と相関係数について行ってみます。 初めに ・正規分布 ・相関係数 を …
-
-
ポアソン分布 possion の計算
確率統計を勉強すると、ポアソン分布いう言葉をよく耳にすると思います。。 データを …
-
-
回帰直線 reglin の使用
データ間に近似直線を引く場合によく用いられます。 実験を行なった場合にはデータの …
- PREV
- 組み込み関数functionによる計算
- NEXT
- 正規分布と相関係数